
Data mining is the systematic process of discovering patterns in data sets through the use of computer algorithms.
An algorithm is a step-by-step procedure for calculations often involving multiple iterations but always having an endpoint where results become available. Computerisation allows for the application of complex algorithms to large data sets, enabling results to be generated very quickly at negligible cost.
Data mining may also refer to the frowned-upon practice of using statistical tools in an ad hoc fashion to find patterns and correlations in the data that support the researcher's current views. This is often associated with a reluctance on the part of researchers to report (or publish) non-significant correlations, a practice which seems widespread according to research by John Ioannidis (author of “Why Most Published Research Findings Are False”).
Although data mining algorithms are usually applied to large data sets, some algorithms can also be applied to relatively small data sets. Data sets used in data mining are simple in structure: rows describe individual cases (also referred to as observations or examples) and columns describe attributes or variables of those cases. For example, a data set might contain rows representing 20 projects in a portfolio and columns representing selected attributes of each project’s context, interventions and outcomes.
The choice of algorithm to use will often depend on the type of data (i.e., nominal, ordinal, ratio or interval) listed in the columns. The ability to work with a mix of data types is particularly relevant to evaluators who may have to be more opportunistic in their use of data than researchers. The ability to use nominal data is important because often categorical data is available to evaluators where variable data is not. For example, it is usually possible to categorise types of interventions or contexts for a project, but more difficult to measure them using a meaningful common unit.
A wide range of data mining algorithms have been developed. The typology by Maimon and Rokach (2010; p.6) is probably the most comprehensive:
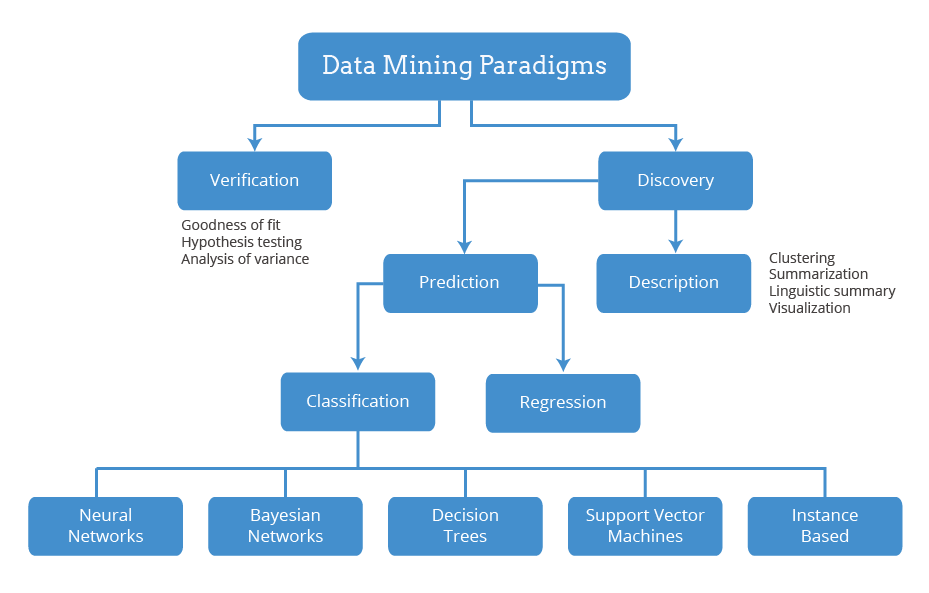
Both functions of data mining algorithms listed under Discovery are relevant to evaluation:
- Description: Clustering algorithms have potential for identifying stakeholder groups in beneficiary populations that do not simply fit under ‘one’ label (e.g., older migrant men who are unemployed). They can also enable identification of groups of projects within diverse portfolios which have sufficient commonality to allow meaningful comparison of effects of interventions or causes of outcomes.
- Prediction: Classification algorithms, such as Decision Trees, can identify multiple configurations of attributes of interventions associated with particular outcomes (with similar results to using Qualitative Comparative Analysis (QCA) and consistent with a Realist Evaluation perspective)
It is worth noting that in a data set with 20 attributes, such as might be collected by a modest baseline survey, there are 220 possible combinations of those attributes (i.e., 1,048,576). So, there are a huge number of possible types of clusters of cases and possible predictable relationships between attributes. A particular theory or hypothesis to be tested in a study will typically focus on a very small proportion of these possible clusters or relationships, so the rest may easily be lost sight of. Cross-tabulation of selected survey responses can provide a wider view, but will usually only explore a fraction of the patterns that might be found in the data set. This is where data mining algorithms can have a complementary role, by providing a quick and efficient means of systematically searching large combinatorial spaces for potentially meaningful patterns.
Although algorithms are automated processes they are not “theory-free”, contrary to some of the claims made about their value when applied to “big data” (see Anderson, 2008). Parameters need to be set for most algorithms and the selection of these can affect the results that will be obtained. For example, the classification accuracy of a Decision Tree model is affected by the tree depth (i.e., the number of branching points – see examples below). Perhaps more importantly, choices also need to be made about what cases and what attributes to include in the data set in the first place and, amongst those, about which to use when using a particular algorithm. There is now a body of literature on systematic ways of addressing choices of attributes, a task which is referred to as "feature selection".
Nevertheless, it is possible to test models (using different parameters and selection of attributes) objectively. Decision Trees and other predictive models are typically using a proportion of a data set known as “the training data set”. The model is then tested for its accuracy using the remaining portion known as the “test data set”. The first, in effect, establish the internal validity; the latter establishes the degree of external validity. Good performance of models on test data sets usually requires avoidance of “over-fitting” of those models to the initial training data.
Predictive models generated through data mining algorithms are not explanatory models, yet they can still be an important tool. There are likely to be many instances where managers of development projects may want to predict people’s behaviour reliably without necessarily expecting to control it (which would require a more explanatory model). For example, how people will react to various public communications or financial incentives. Predictive models do not always need to have high levels of accuracy to be useful. For example, while a surgeon may need 99% certainty, an investor in the stock market can still profit by predictions that are only successful 55% of the time. Predictive models can be developed into explanatory models if there are opportunities to follow up the cross-case analysis by within-case investigations of likely causal mechanisms (e.g., through process tracing methods that look for the presence of necessary and/or sufficient conditions (see also Mahoney, 2012).
In addition to data mining algorithms, packages like RapidMiner also include commonly used statistical functions and data visualisation aids, as well as modules that enable semi-automated data cleaning and other functions to help prepare data sets for analysis. The latter reflects the fact that large data sets often do not come from carefully planned research projects but from the day-to-day operations of organisations or from opportunistic sources such as weblogs and social media records.
Data mining algorithms can work with text as well as other types of data, as noted above. Text mining algorithms are included in packages like Rapid Miner. These read texts and effectively treat each word as an attribute in a data set (known as a token), with each document being a case. Data mining algorithms that can be applied to nominal data can then be used on these data sets. Text mining usually involves more data preparation due to the particularities of language (e.g., punctuation practices), the use of conjunctions and articles, etc. Data mining algorithms can be used to find patterns and relationships within texts, as well as patterns and relationships between texts.
For example, text mining can be used for evaluation by analysing large amounts of unstructured text in open-ended survey responses. Open-ended responses may yield important insights into beneficiaries’ views and opinions on an intervention. Respondents may commonly use a certain set of words or terms to describe the advantages and disadvantages of different aspects of the intervention under investigation. Automated text mining tools allow for the processing of large amounts of unstructured text more quickly and reliably than any manual process.
Until now the main users of data mining are companies with a strong consumer focus –retail, financial, communication, and marketing organisations. Cluster analysis may help inform shops where to display items; prediction models may help with the setting of prices for different products. Data mining algorithms help companies to predict future trends and behaviours that allow them to make proactive, knowledge-driven decisions (such as targeted promotions). By scouring databases for hidden patterns, computerised data mining tools can now provide answers to business questions that used to be too time-consuming to resolve by manual or more consultative methods.
Many of the software packages sold to, and used by, these companies are expensive and not within reach of most evaluator’s budgets. However, there are important exceptions, notably the widely used Rapid Miner package of algorithms which is free and open-source, and undergoing continuous development. Rapid Miner is supported by an array of video tutorials and, more recently, also by detailed guidance (see Mathew North’s “Data Mining for the Masses (pdf)” published in 2012). Data mining packages with free elements are also becoming available for use online (e.g., bigml).
Examples
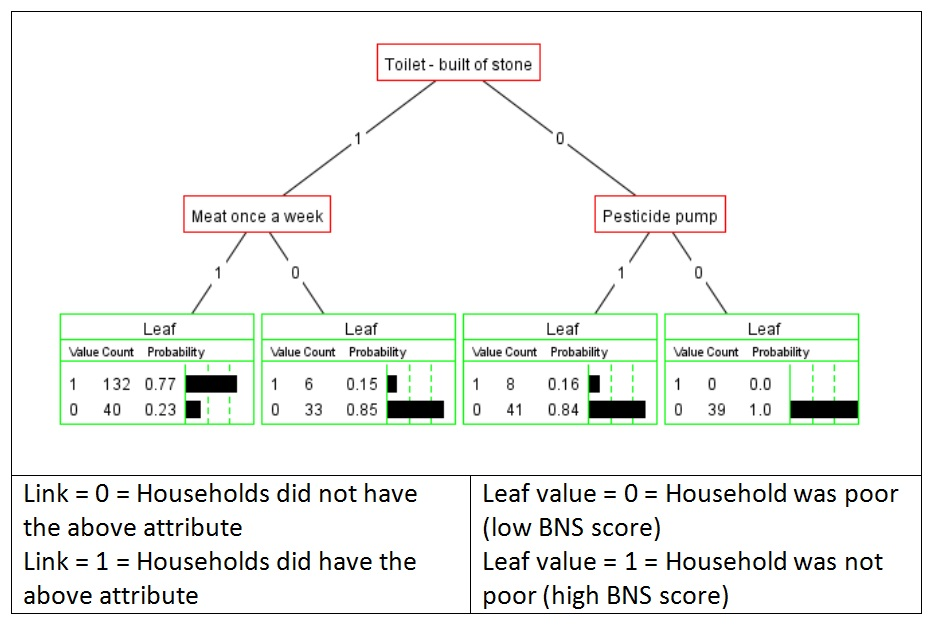
Decision Tree model based on household poverty data from Ha Tinh province of Vietnam in 2006
Data mining methods can be used to extract additional value from existing data sets. In 2006, a survey of 596 households was carried out in Ha Tinh Province, Vietnam. The Basic Necessities Survey only collected categorical data on the possession of 23 different assets and practices and views of which of these were necessities. This was used to develop an index of household poverty status (see Davies, 2007). More recently, this data set was analysed using a Decision Tree algorithm, to identify a classification rule that would best predict whether a household was poor or not (Davies, 2013).
The simple Decision Tree shown below was generated by an analysis of a randomly selected 50% of the 596 survey responses. Reading the tree from the top, we see that if a household has “a toilet built of stone” and they “eat meat once a week” then there is a 77% probability they will be “non-poor”. On the other hand, if a household has neither, there is a 100% probability they will be “poor”. When this simple model was tested against the second half of the data set, its overall accuracy was 82%. More specific measures of the model’s performance can also be calculated, including the proportion of Type I and Type II classification errors.
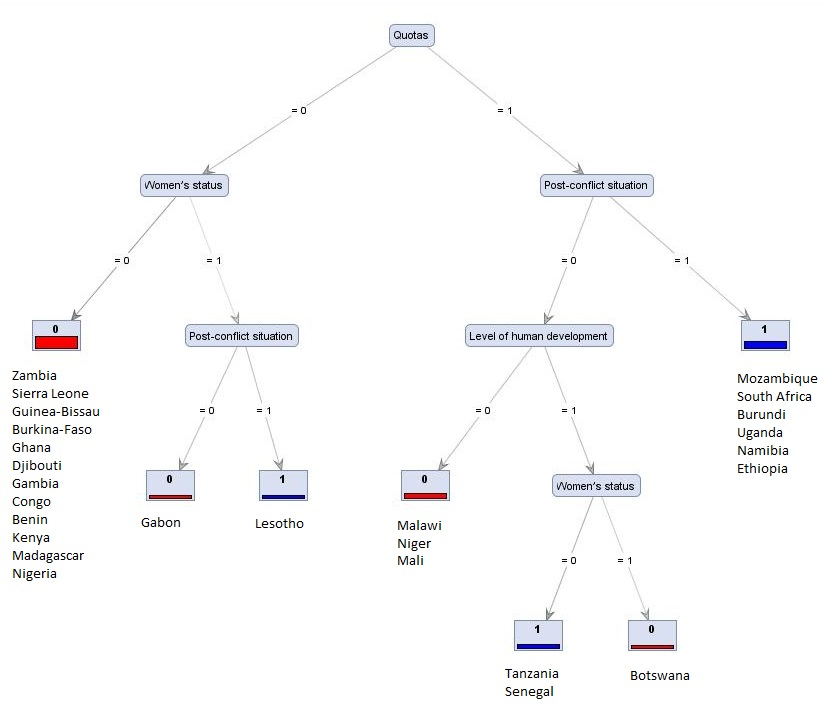
Women’s Representation in Parliament
Data mining methods can also be used to triangulate results of analyses using other methods. Krook (2010) analysed the factors associated with high and low levels of women’s participation in parliament in 26 African countries, using Qualitative Comparative Analysis (QCA). The same data set has since been analysed to produce a Decision Tree model. The two sets of findings, generated by using quite different methods, were in substantial agreement: six of the seven configurations associated with “high levels of participation” or “low levels of participation” were the same. The Decision Tree model is shown below. It could be tested further by seeing how well it is able to predict the known outcomes in other African countries outside the original set of 26 used by Krook.
Advice for choosing this method
Data mining methods are suited to complex settings, where our ability to predict events in advance may be quite limited but where we can, with sufficient data, discover relationships between events after they have occurred.
The use of data mining methods requires existing data sets. However, many organisations will have data sets that have been collected in the past, but which have never been fully analysed. These can provide useful learning opportunities to test out different data mining methods. With the move towards greater transparency and “open data” within government and other circles, it can be anticipated that data sets will become increasingly available in the public domain.
It is also possible to have too much data. For example, project activities that involve the use of financial services or make extensive use of social media. In these circumstances, an organisation may not have the time or resources to analyse all data. Putting these data sets in the public domain, via public data repositories or into data analysis competitions hosted by third parties (e.g., Kaggle), can help ensure that they will get analysed. In Eric Raymond’s words "With enough eyeballs, all bugs are shallow".
Advice for using this method
The selection of what attributes to include in an analysis needs particular care if the intention is to develop a model that has an explanatory function. Including all available attribute data may help develop a workable predictive model but the results will be difficult, if not impossible, to interpret in any causal sense.
A degree of inaccuracy should be accepted. If models are over-fitted to “training data” (i.e., they classify all cases perfectly), they are likely to be poor at generalising (i.e., making accurate predictions about new cases).
Resources
Sources
Anderson, C. (2008). The End of Theory: The Data Deluge Makes the Scientific Method Obsolete. Wired. https://www.wired.com/2008/06/pb-theory/
Davies, R. (2013).Where There Is No Single Theory Of Change: The Usefulness Of Decision Tree Models. Evaluation Connections, June 2013, pages 12-14.
Davies, R. (2007). The 2006 Basic Necessities Survey (BNS) in Can Loc District, Ha Tinh Province, Vietnam. Pro Poor Centre, Ha Tinh.
Ioannidis, J. (2005). Why Most Published Research Findings Are False. PLOS Medicine, published: August 30, 2005, DOI: 10.1371/journal.pmed.0020124.
Maimon, O., Rokach, L. (2010). Introduction to Knowledge Discovery and Data Mining. In: Maimon, O., Rokach, L. (Eds). Data Mining and Knowledge Discovery Handbook. 2nd Edition. New York: Springer, p.1-15.
Mahoney, J. (2012). The Logic of Process Tracing Tests in the Social Sciences. Sociological Methods & Research 41(4):570-597. doi:10.1177/0049124112437709.
McDonald, D., Kelly, U. (2012). “The Value and Benefits of Text Mining”. JISC. http://www.jisc.ac.uk/reports/value-and-benefits-of-text-mining
North, M. (2012). Data Mining for the Masses. Global Text Project. https://www.betterevaluation.org/sites/default/files/2023-05/DataMiningForTheMasses.pdf
Rokach, L., Maimon, O. (2008). Data Mining with Decision Trees: Theory and Applications. World Scientific.
Pang-Ning, P., Steinbach, M., Kumar, V. (2006). Introduction to Data Mining. Pearson Addison-Wesley. Three chapters are available as pdfs, on classification, association analysis and cluster analysis.
Expand to view all resources related to 'Data mining'
'Data mining' is referenced in:
Framework/Guide
- Rainbow Framework :